Pytubes’ Performance¶
To assess performance, a number of sample workloads have been implemented, both in native python, and using pytubes, with their results being compared
Dataset: Pypi download stats¶
Pypi provide package download logs via google bigquery. These tables can be downloaded in a number of formats, including gzipped, line-separated JSON files.
One day’s worth of download data for the 14th December 2017 was taken. Google provided this data as 38 gzip compressed files, totalling 1.2GB (9.3GB uncompressed). How many records?:
import tubes, glob
print(list(tubes.Each(glob.glob("*.jsonz")).read_files().gunzip(stream=True).chunk(1).split().enumerate().slot(0))[-1])
15,612,859
15 million package downloads happened on the 14th December 2017!.
Each row looks similar to this:
{
"timestamp":"2017-12-14 00:42:55 UTC",
"country_code":"US",
"url":"/packages/02/ee/b6e02dc6529e82b75bb06823ff7d005b141037cb1416b10c6f00fc419dca/Pygments-2.2.0-py2.py3-none-any.whl",
"file":{
"filename":"Pygments-2.2.0-py2.py3-none-any.whl",
"project":"pygments",
"version":"2.2.0",
"type":"bdist_wheel"
},
"details":{
"installer":{
"name":"pip",
"version":"9.0.1"
},
"python":"3.4.3",
"implementation":{
"name":"CPython",
"version":"3.4.3"
},
"distro":{
"name":"Amazon Linux AMI",
"version":"2017.03",
"id":"n/a",
"libc":{
"lib":"glibc",
"version":"2.17"
}
},
"system":{
"name":"Linux",
"release":"4.4.35-33.55.amzn1.x86_64"
},
"cpu":"x86_64",
"openssl_version":"OpenSSL 1.0.1k-fips 8 Jan 2015"
},
"tls_protocol":"TLSv1.2",
"tls_cipher":"ECDHE-RSA-AES128-GCM-SHA256"
}
So, many fields, with a nested structure (the nested structure actually doesn’t help pytubes’ performance, so this seems reasonable to have)
Extracting one field¶
Let’s say our analysis just requires a single field of this dataset for processing, for example, the country code, to examine which countries download the most. The python version:
result = []
for file_name in FILES:
with gzip.open(file_name, "rt") as fp:
for line in fp:
data = json.loads(line)
result.append(data.get("country_code"))
with pytubes:
list(tubes.Each(FILES)
.read_files()
.gunzip(stream=True)
.split(b'\n')
.chunk(1)
.json()
.get("country_code", "null"))
results:
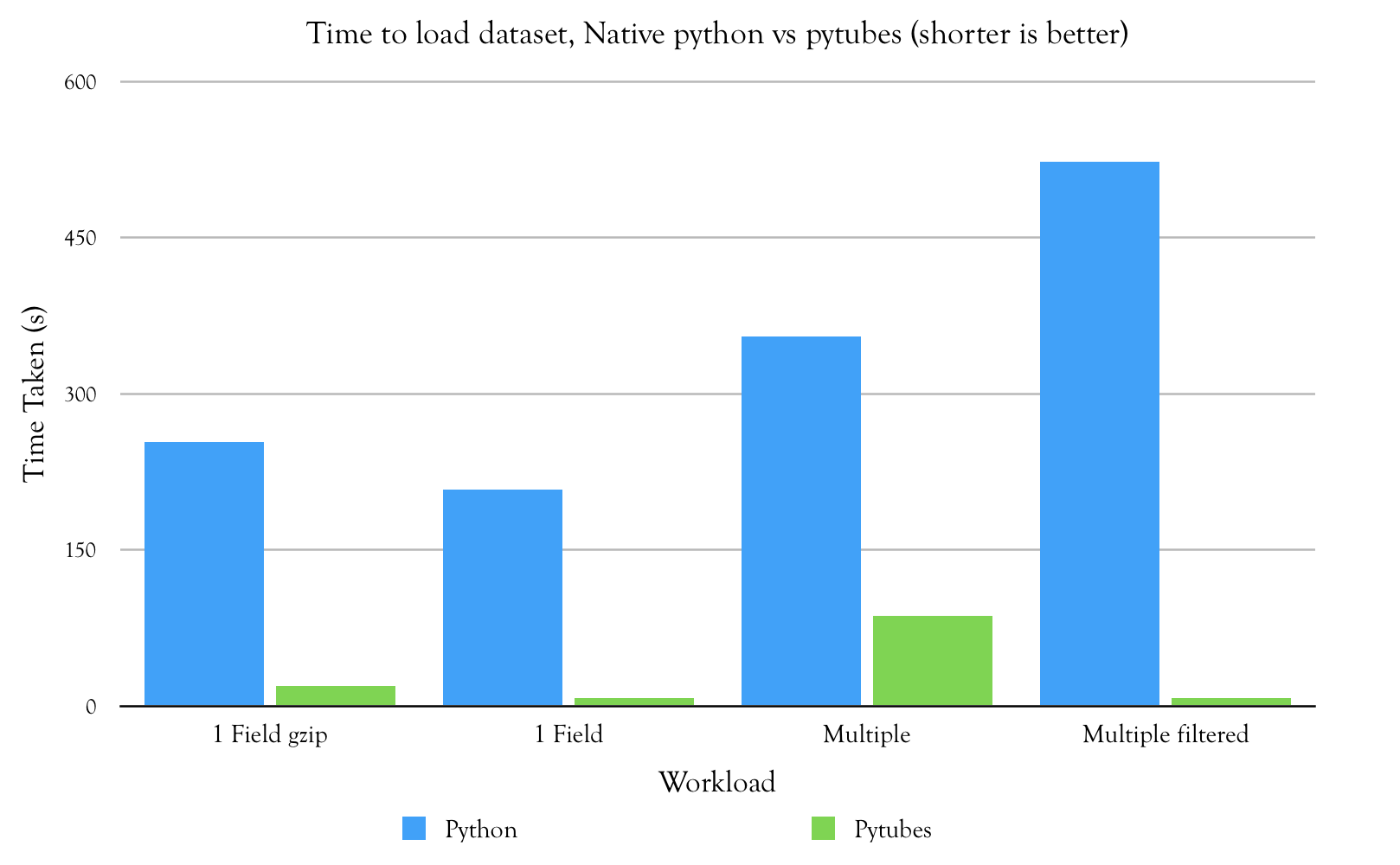
| Version | Pure Python | pytubes | Speedup |
| Time (s) | 254 | 19.6 | 12.9x |
About 1/2 of the pytubes time is spent gunzipping 9GB of data.
Extracting one field without gunzip¶
Doing the same thing as before, but with pre-expanded data gives a different picture:
Python version:
result = []
for file_name in FILES:
with open(file_name, "rt") as fp:
for line in fp:
data = json.loads(line)
result.append(data.get("country_code"))
Pytubes version:
return list(tubes.Each(FILES)
.read_files()
.split(b'\n')
.json()
.get("country_code", "null"))
results:
| Version | Pure Python | pytubes | Speedup |
| Time (s) | 208 | 7.78 | 26.7x |
Extracting multiple fields¶
Rather than just a single field, it may be more useful to extract multiple fields from each record.
In this test, the following set of 12 fields are pulled from each record:
timestamp
country_code
url
file → filename
file → project
details → installer → name
details → python
details → system
details → system → name
details → cpu
details → distro → libc → lib
details → distro → libc → version
and flattened into a tuple, the result is actually discarded (rather than collected into a list, as the memory pressure of loading datasets that large complicate things.)
Code can be seen in the Notebook 3
The performance improvement here isn’t great, as the time is dominated by python allocation overheads.
| Version | Pure Python | pytubes | Speedup |
| Time (s) | 355 | 87 | 4x |
Multiple fields, Filtered¶
If the dataset can be filtered on loading, then we can regain some performance benefits, by avoiding the allocation overhead entirely.
Loading a similar set of fields:
timestamp
country_code
url
file → filename
file → project
details → installer → name
details → python
details → system → name
details → cpu
details → distro → libc → lib
details → distro → libc → version
But only where the country_code is ‘GB’ gives:
| Version | Pure Python | pytubes | Speedup |
| Time (s) | 523 | 7.43 | 70.4x |
Code here: Notebook 4